
We can create the future of science right now
Most of the parts we need are already being built

The bottleneck
At this point it is uncontroversial to say that science needs to stop using the PDF article as the unit of knowledge and currency. The unbearable slowness of scientific publishing, the profit motive and margins. I’m not saying anything new. The PDF also sucks because it’s hard to extract structured information from, which makes it hard to do evidence synthesis. As a result, we do much less evidence synthesis than is needed. And evidence synthesis ultimately undergirds most policy and medical decision making. I can see second by second real time odds for any sporting or newsworthy event, but a school board can’t see the best evidence on whether their 8th graders should be taught algebra. As a society we don’t treat this as an important problem. Again, not controversial.
Not only is the problem well understood, but the solution has already been laid out. What we need is AI-assisted living evidence synthesis - (1) an open knowledge graph of atomic claims (2) claims linked to evidence (3) assessment and synthesis of each piece of evidence (4) continuous updating with new data.
What few realize (yet) is that the technical capacity to build this vision for a significant portion of science already exists. Not only that— scientists and startup teams are already building many of these components. I know this because I’ve been surveying the space and talking to many of the builders. There are some missing pieces: for example evaluations of how well some of the components work. But at this point most of what’s missing is a fully end to end working integration of all of these parts. In the rest of this essay, I’m going to lay out all the parts of a working living evidence layer for science and who is working on them, and propose concrete next steps for building this system.
What’s now possible
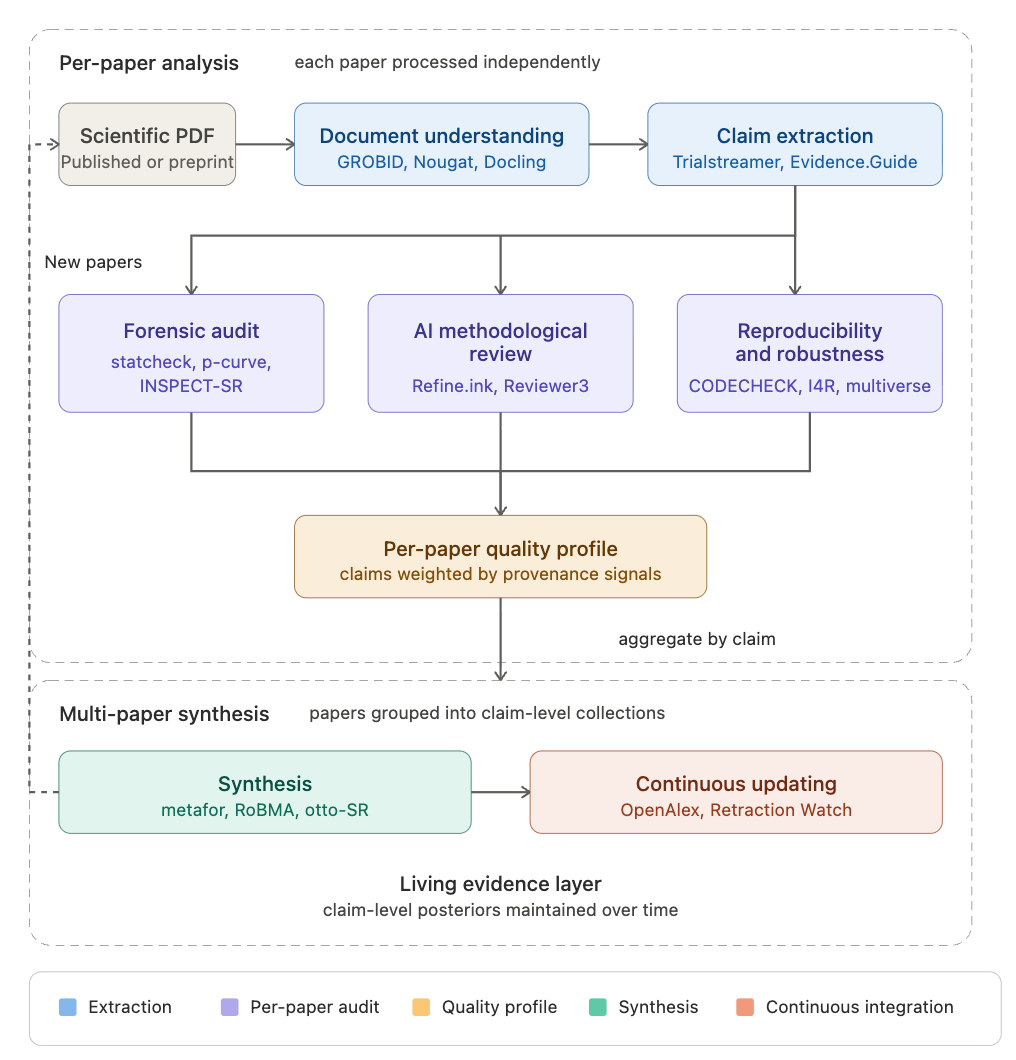
The diagram above outlines the components of a living evidence synthesis platform, including some of the teams working on each component1. Scientific PDFs are processed into claims with associated evidence. The evidence is subjected to a forensic audit, methodological evaluation and robustness and reproducibility checks. Finally it’s given a weight in a continuously updating synthesis. What follows is a description and status of each component and a few of the teams working on them.
Document understanding
The first thing you need to be able to do is turn an article into structured data. Mostly that means parsing PDFs. There are often multicolumn layouts that confuse non-specialized PDF to text processing libraries. For scientific papers, there is the added complexity of parsing formulas and tables and figures. This is a really hot area - there are startups offering APIs, and it seems like a new open source package gets posted to Github every few weeks. What follows isn’t exhaustive. A package called GROBID was the state of the art for a while, they didn’t update their package for nearly two years until very recently. In the meantime reducto.ai released an AI powered PDF extraction API, PaddleOCR became popular, IBM released a model called Docling, and both Mistral and Gemini created models and libraries. I also know of at least one other well-funded psychology research group working on a paper parser. By contrast, there are few open evals in this space, with no extensive evals for complex table comprehension in particular. Nonetheless, I'm confident this will be a solved problem soon, given the combination of LLM advances and developer interest.
Hypothesis level extraction
There has been increasing interest in comprehending the extracted text of papers and linking information to evidence for each hypothesis. A lot of work has already been done. Trialstreamer (Marshall et al. 2020) and RobotReviewer LIVE (Marshall et al. 2023) demonstrated automated extraction of trial population, intervention, and outcome at scale on clinical RCTs. PaperQA2 (Skarlinski et al. 2024) and Ai2 ScholarQA (2024) extended this to retrieval-augmented question answering with citation grounding. Elicit, Consensus, and SciSpace operationalized claim-level extraction for end users. OpenEval (Booeshaghi et al. 2026) is the most recent and most ambitious: 1.96 million atomic claims extracted from 16,087 eLife manuscripts using Claude Sonnet 4.5, grouped into ~299,000 results, with LLM evaluations showing 81% agreement with human peer review on a 2,487-paper subset. None of these solutions link claims to test statistics, as you would need to evaluate randomized control trials. This is why I built the evidence.guide API - to extract hypotheses and associated test statistics from behavioral science papers. The best public eval of this kind of extraction I’m aware of comes from the recent SCORE project - they had humans code thousands of psychology papers to extract their claims by hand. It would be extremely helpful to the world if all scientific PDFs were available as structured open data. I’ve been working to make this happen, both directly at Berkeley and through coordination with large entities I can’t yet speak of; as hard as it is to do, I think it’s possible2.
Forensic audit
A lot of work has been done on forensic audit, but some gaps remain. Of course, for biology papers that rely on images for evidence, there are a variety of tools (notably Proofig and ImageTwin) to spot anomalies. These are still well short of what sleuths like Elizabeth Bik can do on her own, but these tools are constant companions among fraud analysts. There’s someone working on auditing Excel files for anomalies, and a number of teams are automating numerical checks like GRIM and SPRITE, including Scrutiny project, the INSPECT-SR team as well as statcheck. The regcheck team is building a way to use AI to compare preregistrations to analyses in papers, to ensure there aren’t significant deviations. Nonetheless, there are many other kinds of anomalies to screen for, both public and less publicly known. And there are no formal evals for anomaly detection that I’m aware of. Still, there’s a lot to draw from in this space and I’m pretty certain we will be able to scan papers for most kinds of obvious anomalies in the near future.
Methodological review
This area has been white hot, though I fear for many of the startups in this space, because this capability may become commoditized. There are at least six different AI peer review companies, including Refine.ink, Reviewer3, ReviewerZero.ai, Q.E.D. Science, Paper Wizard, and Isitcredible. Coarse (a pun on refine) was also recently created as an open source alternative. These systems provide qualitative feedback on the content of papers, spotting methodological weaknesses and mathematical errors. They seem to work pretty well, and many academics report bitterly that they exceed the average quality of typical peer reviewers. But there are few evals here either. What evals exist so far involve using LLM-as-judge (circularity problems abound) or comparing against human reviews of questionable quality. What you’d ideally want is an eval that measures capturing known errors in papers3.
Reproducibility and robustness
Another active area has been using AI agents to automate computational reproducibility4 and robustness5 checks in papers that report numerical results. For more recent papers where data and code are available, AI agents can see whether they can re-run the analyses and produce the numbers reported in the published paper. In addition to a handful of individual academics who have been experimenting using Claude Code for this, the Institute for Replication is a leading group working on building an end to end system. The evals related to this problem are the most mature, with CORE-Bench (Siegel, Kapoor, Narayanan 2024) and PaperBench (OpenAI 2025) available to benchmark agents on this task. There is also work on getting AI agents to test alternative ways of analyzing the data to ensure the results are robust to small analytic design choices.
Synthesis
This is the most underdeveloped area where significant investment is required. Although some automated evidence synthesis systems exist — for example, otto-sr is building an AI agent to write systematic reviews — none of these incorporate the full range of paper level signals to weight evidence appropriately. Nor is there anything like an eval or a gold standard for a good systematic review. Arguably Cochrane reviews are the closest we have to gold standard human systematic reviews, though I’ve heard academics in the know complain about their uneven quality. A key question for a synthesis platform is how to weight anomalies and methodological issues in assessing the quality of a piece of evidence. This is an unsolved problem and one I’m very keen to work on.
Continuous updating
There are many pieces of basic infrastructure available for monitoring for new research and initiating updates. OpenAlex is the current open citation graph. Retraction Watch integrated into Crossref in October 2023. Scite tracks how citations support, contrast, or mention prior claims. The Living Evidence Network demonstrated continuous-update workflows in clinical guidelines. Engineering this is a relatively straightforward task.
When you look over this technical architecture and all the progress being made, it’s hard not to be optimistic that a living guide to scientific evidence will be built.
The stakeholders are ready
The social infrastructure for this is starting to coalesce — it’s not just a pie in the sky academic exercise to imagine this coming into existence. Institutions like the Center for Open Science, the Institute for Replication, the INSPECT-SR, the Living Evidence Network and more are all working on scaling work to improve research quality.
Funders are also aligned. The Sloan Foundation has funded living evidence work through COS. Coefficient Giving supports the Institute for Replication and COS. The Astera Institute and the Institute for Progress has shown interest in this space. NIH has established an Office for Replication and Reproducibility. Although there are (very unfortunately) serious headwinds in science funding generally, there is an active group of funders interested in metascience.
A brief word about what I’ve been doing at RDI. First, as a Visiting Scholar at Berkeley I’ve been actively figuring out how a non-profit and a public university can conduct and make public the results of large-scale academic article data mining. With some of the money I raised from donors, I commissioned a legal analysis of recent case law and publisher text data mining (TDM) agreements in order to understand whether a massive open data mining of academic articles is possible (with caveats, it is). I’ve also been working to bring together stakeholders in this space, and identify gaps. I’ve also been doing some software development in this space, with more to come.
A pilot proposal
The assumption undergirding all of this is that an AI, given all this information, would make the right judgment about a scientific claim with lots of conflicting evidence, weighing all the factors appropriately. That’s the hypothesis we need to test.
Randomized control trial research is the best place to focus on first. RCTs are used to make many of the important decisions in society - from medical trials to public policy changes. And they use a relatively uniform set of inferential statistics with lots of known and available diagnostics. Behavioral science experiments, within the broader realm of RCTs, should be first used as a testbed whose results can be generalized. Because behavioral science is at the vanguard of open science practices, replications abound (there are thousands of them) to serve as ground truth training data.
Key Hypothesis
Therefore the pilot would test, in behavioral RCTs that have been replicated, whether the quality of evidence for a claim can be used to accurately predict whether that claim will replicate.
Secondary Hypotheses
Compared to claims that replicated, non-replicated claims demonstrate a greater share of forensic anomalies in their source literatures.
Hypothesis level claim and statistic extraction is accurate enough to scale living evidence without onerous human review costs.
Replication prediction is more accurate than prediction markets6 or journal prestige.
If all the different quality signals we gather do accurately predict which studies will replicate, then we can use that model to score evidence to power the living evidence layer.
Why this is informative regardless of outcome
If the pilot succeeds, the architecture extends to medical RCTs (where Living Evidence already operates and integration is mostly about claim representation), then to slices of basic biology with stable replication structure. If it fails, the field learns which quality signals are load-bearing and which ones metascience has oversold. Either result is a contribution to knowing what the literature supports.
Implications for funders
Because this burgeoning ecosystem of builders already exists, a well-informed philanthropic or government funder could play a crucial catalyzing role in bringing this future about. They could play at least three roles: creating open structured datasets, publishing open benchmarks and incentivizing the solving of key technical challenges.
First, open archives of papers that the government maintains, like PubMed, could be turned into structured data amenable to large scale metascience and claim aggregation. I know the US government already has an interest in doing this, though some key open questions remain unanswered. How do you determine the best models and systems for accurately extracting information from papers? How can you establish a robust way to allow researchers to flag errors and correct them? And finally, how do you create a legal regime in working with publishers to maximize the scope of available papers? For the latter, a university or a private philanthropy may be better positioned to make structured data publicly available under journal subscription terms or fair use.
Philanthropists or government funders could also coordinate to create or commission benchmarks that evaluate whether important problems have been solved. For example, an open benchmark for claim extraction from a range of different scientific article types would be extremely helpful. Ensuring the underlying data are accurate is vital for creating these evaluations. I’ve discussed opportunistically using various human-created datasets for this purpose, but a consistent problem is that errors in human data make it difficult for them to serve as a gold standard.
Finally, with structured data and benchmarks available, the government or private philanthropy could use them to incentivize groups to develop machine learning systems that meet these benchmarks. Prizes are one potentially valuable tool for this. For example, you could establish a prize for a system that accurately updates a living meta-analysis for a small set of claims. Prizes are particularly useful as signals of problem importance, and can help create vibrant ecosystems of public and private research—see, for example the role the government played in kickstarting the current work on nuclear fusion.
Conclusion
The drawbacks of the current scientific publishing system are known. Scientists agree, metascientists agrees, philanthropists agree: the published PDF plus citation graph isn’t the right substrate for maintaining a representation of the evidence base in science. The pieces needed to build the alternative either already exist or are rapidly taking shape. The community is forming around exactly this problem, with concrete partnerships and shared infrastructure. A pilot should start on behavioral science RCTs because that's the slice of empirical science most amenable to legibility, where replication ground truth is richest, and where the failure modes are best documented. What's been missing is the galvanizing mission to assemble these pieces into something that works. That's what I'm proposing to build.
I have a broader field map that I’ll release publicly soon. This is me, building in public!
If this is something that you are excited about, please reach out and talk to me.
More on this very soon too!
This tests whether, given the code and the data, you can get the same statistics as reported in the published paper.
This tests whether the results are the same as a paper’s given alternative analytical decisions in conducting the analysis (like outlier omission). Closely related is the idea of a “multiverse” where you come up with many different ways of answering the same underlying research question with the same data, and test whether the results hold in all those alternative methods. There’s been work on the latter as well.
Some of the replications, e.g. those from the SCORE project, had paired the experiments with forecasts from prediction markets. So we get to look at this for free.